Using Data Mining and Machine Learning to Detect Cryptocurrency Risks
Written by Lai Yan Jean, Lee Jing Xuan, Valary Lim Wan Qian, and Xu Pengtai
Cryptocurrency and the Need to Regulate It
Cryptocurrency is a medium of exchange (an alternative form of payment) that exists in the digital world and relies on encryption to make transactions secure. The technology behind cryptocurrency allows users to directly send the currency to others without going through a 3rd party, such as a bank. To make these transactions, users will need a digital wallet that can be set-up without the need to provide personal details such as an identification number or credit score, therefore allowing users to be pseudo-anonymous.
For the average cryptocurrency user, this anonymity provides peace of mind that their personal information or transaction data will not be stolen by hackers. However, this increased anonymity in transactions is also susceptible to be abused by criminals to carry out illicit activities such as money laundering and terrorist financing. Such illicit activities result in significant losses to both blockchain wallet users as well as the cryptocurrency entities. While regulatory bodies like the Financial Action Task Force (FATF) have introduced standardised guidelines in the regulation of these entities, monitoring the cryptocurrency space is a challenging task due to the significant number of cryptocurrency entities and transactions that occur every day.
Our Solution
There is therefore interest to leverage open source information, e.g. news websites or social media platforms, to identify possible security breaches or illicit activities. In collaboration with Lynx Analytics, we (a team of students from the National University of Singapore) have worked to develop an automated pipeline to scrape open source information, predict the risk score of each news article, and flag out risky articles. This pipeline will be integrated into the Cylynx platform (https://www.cylynx.io/) a tool that Lynx Analytics has developed to help regulatory bodies monitor blockchain activities through the use of various information sources.
Data Scraping of Open Source Information
We identified 3 categories of open source data that could provide valuable information to aid in detecting suspicious activities in the cryptocurrency space. These categories are:
- Conventional news sites e.g. Google News, which would report major incidents of hacks.
- Cryptocurrency-specific news sites e.g. Cryptonews and Cointelegraph, which are more likely to cover news on smaller entities and minor security incidents.
- Social media sites e.g. Twitter and Reddit, where cryptocurrency owners may post about hacks before official releases of hack news.
The contents of the articles and social media posts were retrieved and then used to develop a sentiment analysis model. The model assigns a probability of risky activities to the entity mentioned in the article.
Sentiment Analysis Model
We attempted four different Natural Language Processing tools for sentiment analysis, namely VADER, Word2Vec, fastText and BERT models. After evaluating these models through key selected metrics (recall, precision and F1), the RoBERTa model (a variant of BERT), performed the best and was chosen as the final model.
The RoBERTa model processes the text of a news article (title and excerpt) or a social media post, and assigns a risk score for the particular text. As the text has been tagged to an entity during the data collection process, we now have a relevant risk indicator for a crypto entity. At the later stage, we combine the risk scores from multiple texts to give an overall risk score for an entity.
RoBERTa is originally a sentiment analysis model built using the neural network structure, we map the last layer to our labelled risk scores to customise it to the context of risk scoring. In order to improve the model’s generalisability on future textual data, we performed several text processing methods, namely replacing entity, removal of url and replacement of hash. We then proceeded with the risk scoring using this best-performing model.
Risk Scoring
Each article now has an associated source (news/reddit/twitter), a probability of risk, and a count, that refers to the number of times the article was reposted, shared, or retweeted. To convert these risk probabilities to a single risk score for a cryptocurrency entity, we first scaled the article’s probability values to a range of 0 to 100, and obtained a weighted average for each source that combines the article’s risk score and count. A weighted average was used to place greater importance on articles with a higher count as the number of shares are a likely indication of article relevance or significance.

After computing the risk score of each source, we take a weighted sum of each source to get the entity’s overall score, using the following formula:
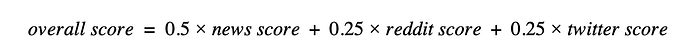
Traditional news sources are given a higher weightage because these sources are more likely to report significant security breaches (as opposed to individual user hack events).
Effectiveness of Our Solution
We tested our solution on a list of 174 cryptocurrency entities from 1 January 2020 to 30 October 2020, and compared the results with known hack cases within that time period. We found that our risk scoring method performed fairly well, identifying 32 out of the 37 known hack cases. We also analysed the effectiveness of our solution for individual entities. The graph below shows the risk score of Binance from 1 January 2020 to 30 October 2020. The dotted red lines represent the known hack cases. From the graph, we observe that our solution reported increased risk scores for 4 of the 5 known hacks. There are also several spikes that do not coincide with known hack cases. However, this does not pose a major problem since it is more important for our model to identify as many hacks as possible and reduce the number of unidentified hacks.
Interesting Findings
During the risk scoring process, we observed that risk scores of larger entities tend to have a larger proportion of false positives recorded compared to the smaller ones. This is because larger entities are talked about more and would therefore have more negative posts and false rumours that contribute to the higher inaccuracy rate.
Another interesting trend worth highlighting is that there are usually a few distinct spikes surrounding a hack. This is due to the difference in reaction time among the different data sources. Social media sites Twitter and Reddit are usually the first to see a spike when high-risk events occur, as users would make posts raising the abnormalities that they observe such as an entity’s site going down without prior notice to the users. Official news is typically released later on after an official statement has been made.
Limitations
We identified two potential limitations of our solution, the first being the need to maintain the scrapers constantly. Website designs may change over time, and the scrapers for those websites would need to be updated in order to ensure that the relevant information will still be retrieved for the purpose of risk scoring.
The second limitation is that it is challenging to verify whether an article has been correctly tagged to a cryptocurrency entity. For example, an article that reports suspicious activity in Bancor may also mention Binance for an unrelated incident. Our solution would wrongly tag the news for both entities and flag Binance as risky even though it is not the key subject in the text. However, this is not a major limitation as we are using only the titles and excerpts for news articles for risk scoring, which will usually only contain the key message of the article.
Conclusion
Our project has allowed regulators to easily tap into open source information to better identify risky events occurring in the cryptocurrency space. We provide a language model that analyses the articles and predicts a risk score, and methods to aggregate these scores based on entity and source information. These methods have all been weaved into an automated pipeline that can be run end-to-end. The integration of this project in the Cylynx platform would complement its existing functionalities and offer tremendous help for regulators in the identification of risky cryptocurrency entities.
You can access the scripts for our project on Github or our socials in the links below.
Project Github: https://tinyurl.com/lynx-blockchain-risk-scoring
Lai Yan Jean | Github | LinkedIn
Lee Jing Xuan | Github | LinkedIn

